· Andreas Schwarz · Automatisierung & Workflows · 8 min read
Probleme erkennen: Monitoring für Automatisierung
Frühzeitiges Monitoring schafft Vertrauen, stabilisiert Prozessautomatisierungen und senkt Ausfälle.

Teaser
Monitoring macht Prozessautomatisierung zuverlässig und vertrauenswürdig. Wer früh Abweichungen erkennt, verhindert Störungen, schützt Serviceziele und spart Nacharbeit. Dieser Beitrag zeigt, was überwacht werden sollte, wie Sie sinnvolle Kennzahlen mit Schwellwerten definieren und welche technischen Optionen ohne großen Aufwand funktionieren. Mit klaren Rollen, datenschutzkonformer Protokollierung und einer einfachen Eskalationskette schaffen Sie schnell Wirkung. Starten Sie klein, lernen Sie aus Vorfällen und bauen Sie Schritt für Schritt ein skalierbares Monitoring auf.
Probleme erkennen: Monitoring für Automatisierung
Warum frühes Monitoring in der Prozessautomatisierung zählt
Automatisierung entfaltet ihren Nutzen erst, wenn sie stabil läuft. In KMUs mit begrenzten IT-Ressourcen zählt daher ein frühes, schlankes Monitoring, das Ausfälle, Qualitätsprobleme und Effizienzverluste sichtbar macht, bevor sie Kunden oder Mitarbeitende treffen. Statt alles zu messen, fokussieren pragmatische Teams auf wenige, aussagekräftige Signale: Verfügbarkeit kritischer Prozessketten, Durchlaufzeiten, Fehler und Datenqualität. Diese Größen decken die meisten Störungen ab und sind schnell umsetzbar. Datenschutzanforderungen, Revisionssicherheit und klare Verantwortlichkeiten kommen hinzu, die das Monitoring strukturieren, statt es zu erschweren.
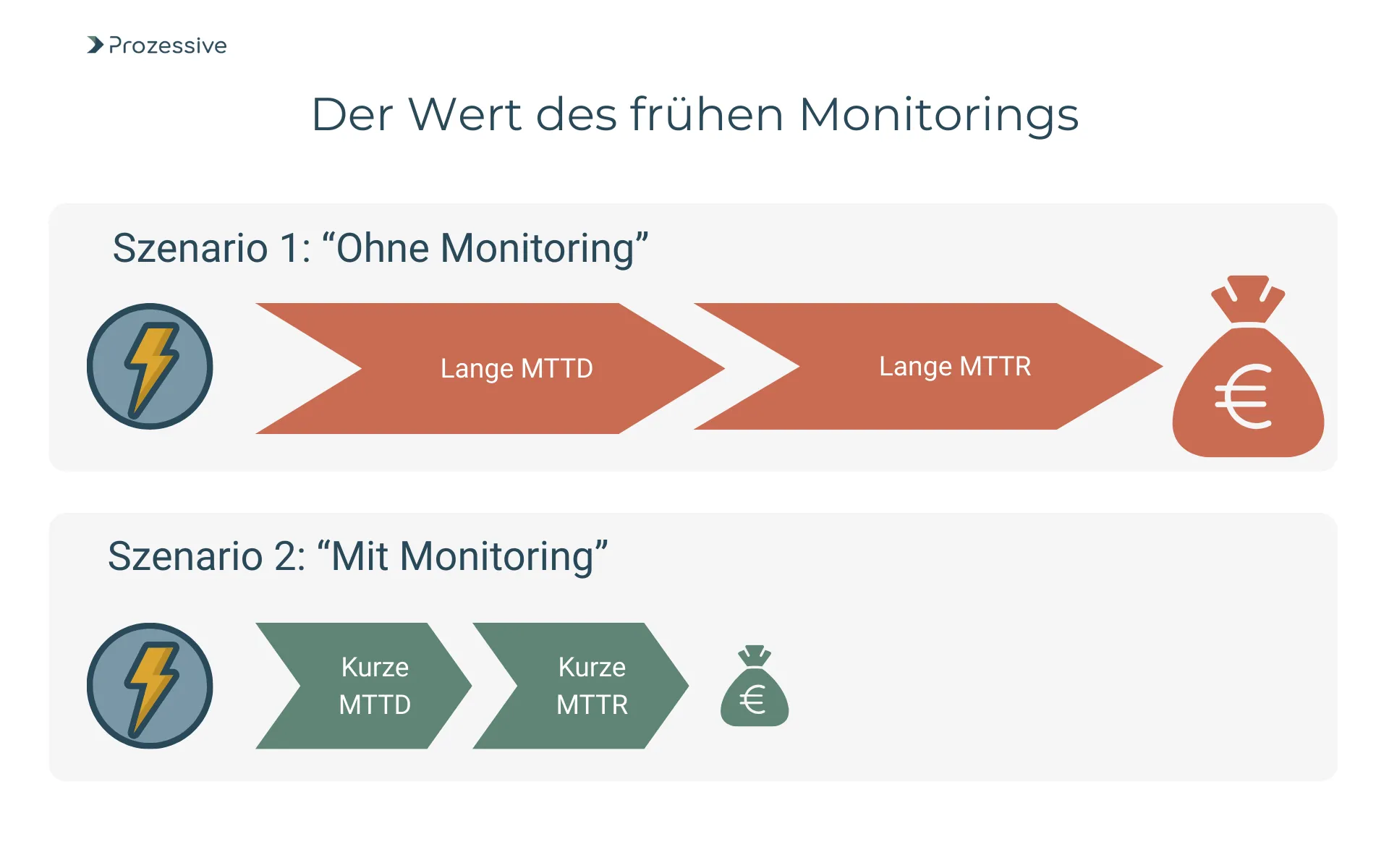
Früh erkannte Abweichungen sind am günstigsten zu beheben: messen, alarmieren, handeln.
Ein frühes, aktives Monitoring senkt die mittlere Zeit bis zur Erkennung (MTTD, Mean Time to Detect) von Fehlern und verkürzt die mittlere Zeit bis zur Wiederherstellung (MTTR, Mean Time to Restore). Beides reduziert Folgekosten, vermeidet SLA-Verstöße und erhält Vertrauen in die Prozessautomatisierung. KMUs erreichen mit einfachen Schwellenwerten und Alarmen spürbare Verbesserungen, bevor komplexe Analytik nötig wird. Entscheidend ist nicht Perfektion am ersten Tag, sondern ein robustes Minimum, das permanent im Einsatz ist. So entsteht Routine und damit Verlässlichkeit.
Was überwacht werden muss, von Prozessen bis Schnittstellen
Gute Überwachung beginnt bei der End-to-End-Sicht. Relevant ist nicht nur, ob ein einzelner Bot, eine Regel oder ein API-Call läuft, sondern ob der gesamte Prozess termingerecht und qualitativ korrekt durchläuft. Das umfasst Eingangsdaten, Orchestrierung, betroffene Systeme und menschliche Mitwirkungen. In der Praxis sind es oft Schnittstellen, Queues oder Berechtigungen, die Probleme verursachen. Wer hier Transparenz schafft, erkennt Störungen früher und kann sie zielgenau beheben.
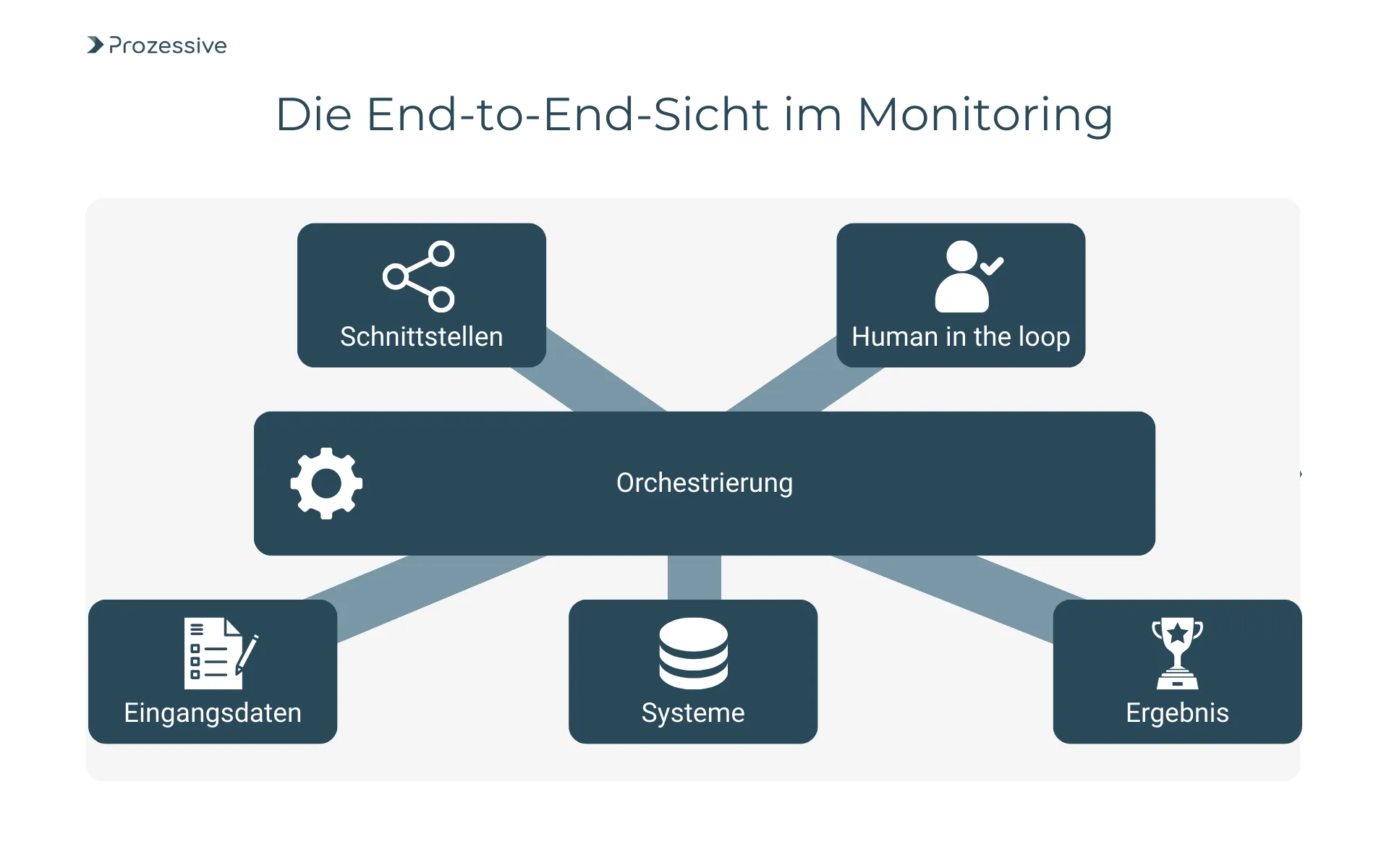
Wichtig sind zudem externe Abhängigkeiten. Wenn eine vorgelagerte Stammdatenschnittstelle stockt oder ein nachgelagertes ERP Update-Fenster hat, betroffen ist die gesamte Kette. Gleiches gilt für Human-in-the-Loop-Schritte: Steigende manuelle Freigaben oder Korrekturen sind wertvolle Frühindikatoren.
Ergänzend lohnt der Blick auf die Folgen von Veränderungen: Nach Releases ist die Fehleranfälligkeit erhöht, weshalb verstärktes Monitoring in den ersten 24 bis 72 Stunden sinnvoll ist. Diese Sicht verhindert, dass Symptome mit Ursachen verwechselt werden.
Frühwarnsignale und Anomalien: Von Schwellwerten zur Mustererkennung
Ein praktikabler Start sind Schwellwerte und einfache Regeln. Beispiele hierfür sind Fehlerraten über einem fixen Schwellwert, wachsende Queue-Längen, längere Durchlaufzeiten oder die Bewertung des SLA-Risikos basierend auf der Restzeit. Diese Werte lassen sich aus Logs, Ereignissen und Metriken ableiten. Mit Betriebsdaten über einige Wochen bilden Sie Referenzwerte und ermöglchen das Erkennen zeitbezogener Muster. Darauf aufbauend lassen sich aus Abweichungen Warnungen und abgestimmte Eskalationen auslösen. Diese Methode bleibt verständlich, auditierbar und ist mit begrenzten Ressourcen umsetzbar.
Für einen Großteil der KMU-Use-Cases reichen zunächst einfache Modelle, die wenige, klar dokumentierte Regeln kombinieren. Wichtig ist, Entscheidungen nachvollziehbar zu halten. So bleibt die Eingreifschwelle verständlich, und Sie können Fehlerursachen systematisch adressieren.
Kennzahlen und Schwellwerte
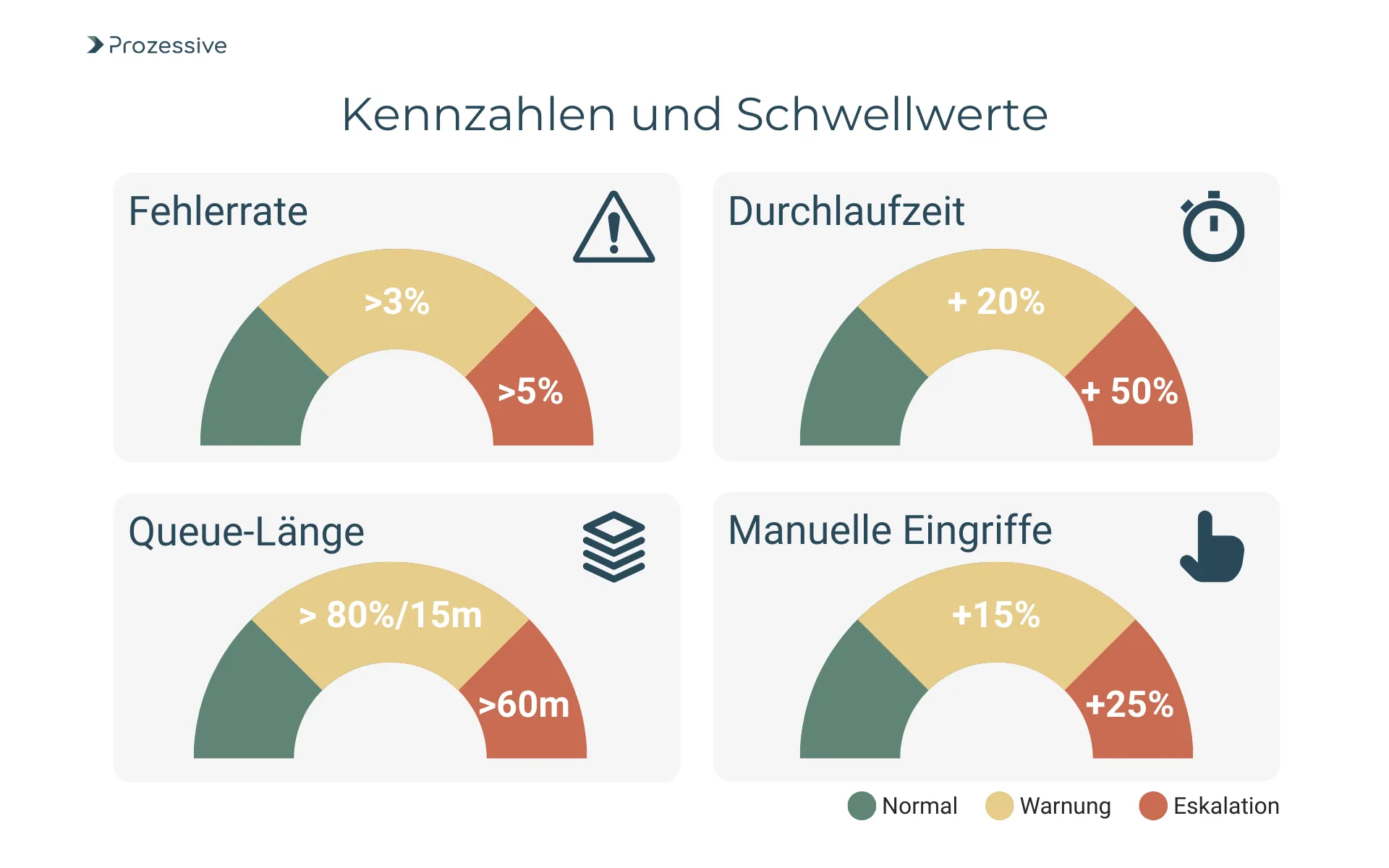
Klare Kennzahlen sind die Basis jeder Steuerung. Sie sollten leicht zu erfassen, eindeutig zu interpretieren und eng an Prozessziele gekoppelt sein. Beginnen Sie mit einer kleinen, belastbaren Auswahl, die Qualität, Zeit und Stabilität abdeckt. Setzen Sie bewusst großzügige Frühwarnbereiche, um unnötige Alarme zu vermeiden und Kapazitäten zu schonen. Die folgenden Spannbreiten sind als Annahmen zu verstehen und dienen der ersten beispielhaften Orientierung. Passen Sie sie an Volumen, Kritikalität und Reifegrad Ihrer Automatisierung an.
- Fehlerrate/Exceptions: Warnung ab 1 bis 3 Prozent über Referenz, Eskalation ab 5 Prozent
- Wiederholungsrate/Retry-Quote: Warnung ab 2 Prozent, Eskalation ab 5 Prozent
- Queue-Länge: Warnung bei >80 Prozent Auslastung länger als 15 Minuten, Eskalation bei >60 Minuten
- Durchlaufzeit/Lead Time: Warnung bei +20 bis +30 Prozent zur Referenz, Eskalation bei +50 Prozent
- Termintreue/SLA-Erfüllung: Warnung bei >10 Prozent prognostiziertem SLA-Risiko, Eskalation bei >20 Prozent
- MTTD: Ziel <5 Minuten für kritische Flows, Warnung bei >15 Minuten
- MTTR: Ziel 30 bis 60 Minuten für hohe Priorität, Eskalation bei >2 Stunden
- Change Failure Rate: Warnung ab 15 Prozent fehlerhafte Changes, Eskalation ab 25 Prozent
- Datenqualitätsfehler: Warnung ab 0,5 bis 1 Prozent invalide/duplizierte Eingaben
- Anteil manueller Eingriffe: Warnung ab +10 bis +15 Prozent Human-in-the-Loop, Eskalation ab +25 Prozent
Diese Kennzahlen sind nur dann wirksam, wenn sie sichtbar sind und belastbare Eskalationsregeln besitzen. Prüfen Sie sie monatlich in einem kurzen Review und passen Sie Schwellwerte an die Realität an. Reduzieren Sie die Anzahl aktiver Alarme, wenn diese nicht zu Handlungen führen. Bauen Sie Feedback aus Incidents in Runbooks ein, damit die Wiederherstellung zuverlässig schneller wird. Stabilität entsteht durch üben, nicht durch Excel-Listen.
Umsetzung: Von Quick Wins zu skalierbaren Routinen
Die Einführung gelingt am besten in kleinen Schritten. Starten Sie mit einem kritischen End-to-End-Flow, etablieren Sie minimale Überwachung, klare Alarme und dokumentierte Gegenmaßnahmen. Nutzen Sie vorhandene Logs und vermeiden Sie schwere Plattformwechsel zu Beginn. Entscheidend ist der Handlungsbezug: Jede Kennzahl braucht eine definierte Reaktion. So entsteht Vertrauen in die Prozessautomatisierung und die Bereitschaft, Monitoring auf weitere Prozesse auszurollen.
- Zielbilder und SLAs definieren: End-to-End-Ziele, Kritikalität, OLA/SLA, Verantwortliche
- Metriken, Logs und Events erfassen: minimalinvasiv, standardisierte Felder, Korrelation ermöglichen
- Alarme, Runbooks und Eskalation: klare Schwellen, Bereitschaftszeiten, Kommunikationswege
- Dashboards und Reviews: Live-Sicht für Betrieb, wöchentliche Kurzreviews, monatliche Service-Reviews
- Test- und Release-Checks: Smoke-Tests, verstärktes Post-Release-Monitoring
- Rollen und Verantwortung: Prozesseigner, IT-Betrieb, Fachbereich, Incident-Manager, Datenschutz
- Datenschutzprüfung: Datenminimierung, Speicherfristen, Zweckbindung, Verzeichnis der Verarbeitungstätigkeiten
- Pilot und Skalierung: 1 Flow stabilisieren, Muster verallgemeinern, Standards dokumentieren
- Schulung und Enablement: Alarmhygiene, Runbook-Übungen, Lessons Learned in KVP aufnehmen
Nach vier bis acht Wochen sollte der Pilot stabil laufen und Kennzahlen belastbare Referenzwerte liefern. Zwei bis drei weitere Prozesse lassen sich anschließend mit geringem Zusatzaufwand einbinden, wenn Datenfelder, Alarme und Runbooks wiederverwendet werden. Halten Sie die Governance schlank und dokumentieren Sie nur, was Sie wirklich betreiben. So entsteht eine Routine, die trägt, ohne das Team zu überlasten.
Technologieoptionen für Monitoring
Technologie folgt dem Zweck. Es zählt was schnell einsatzfähig, verständlich und bezahlbar ist. In vielen Fällen reicht eine Kombination aus vorhandenen Plattform-Metriken, zentralem Logging und einem einfachen Dashboard. Bei wachsender Komplexität können spezialisierte Werkzeuge und Dienste mehr Transparenz liefern. Entscheidend ist Vendor-Neutralität in der Methodik: End-to-End-Denken, konsistente Felder, klare Alarme, reproduzierbare Runbooks. So bleiben Sie beweglich, auch wenn Tools wechseln.
| Option | Eignung für KMUs | Stärken | Risiken/Hinweise | Kostenrahmen |
|---|---|---|---|---|
| Plattform-eigenes Monitoring | Gut für Start und einzelne Lösungen | Schnell verfügbar, geringer Einrichtungsaufwand | Insellösungen, begrenzte End-to-End-Sicht | Niedrig, meist in Lizenzen enthalten |
| Zentrales Logging + Dashboarding | Breite Basis, skalierbar | Einheitliche Felder, Korrelation, flexible Dashboards | Pflege von Schemas, Rechte- und DSGVO-Handling nötig | Niedrig bis mittel je nach Umfang |
| APM (Application Performance Monitoring)/Observability | Für kritische, komplexe Flows | Tiefe Traces, Service-Maps, Anomalien | Einarbeitung, laufende Kosten, Datenmengen | Mittel bis höher, nutzungsabhängig |
| Cloud-native Services | Für Cloud-Workloads | Gute Integration, Auto-Skalierung, Alarme | Plattformbindung, Datenexport prüfen | Niedrig bis mittel, nutzungsbasiert |
| Leichtgewichtiges Custom Monitoring | Nischen und Spezialfälle | Maßgeschneidert, fokussiert, kosteneffizient | Wartungslast intern, Bus-Faktor | Niedrig, primär Initialaufwand |
Bewerten Sie Optionen entlang Ihrer kritischen Prozesse, nicht entlang zahlreicher Marketing-Versprechen. Eine kleine Konzept-Phase mit realen Alarmevents klärt Eignung, Datenqualität und Bedienbarkeit. Halten Sie die Zahl der Werkzeuge gering und standardisieren Sie Formate für Logs, Metriken und Tags. So bleibt der Betrieb übersichtlich und auditierbar.
Governance, Datenschutz und Verantwortlichkeiten
Monitoring ist Verarbeitung betriebsrelevanter (und ggf. personenbezogener) Daten und benötigt klare Leitplanken. Erstellen Sie eine Zweckbeschreibung, minimieren Sie Dateninhalte und begrenzen Sie Aufbewahrungsfristen. Pseudonymisieren Sie, wo möglich, und trennen Sie technische IDs von Klardaten. Pflegen Sie das Verzeichnis von Verarbeitungstätigkeiten, definieren Sie Löschkonzepte und schützen Sie Protokolle vor unbefugtem Zugriff.
Rollen sind ebenso wichtig wie Technik. Der Prozesseigner verantwortet Ziele, Kennzahlen und Runbooks. IT-Betrieb und Incident-Management sichern 24x7- oder Geschäftszeiten-Bereitschaft, je nach SLA. Datenschutz und Informationssicherheit prüfen Zwecke, Rechtsgrundlagen und technische-organisatorische Maßnahmen. Regelmäßige Release- und Incident-Reviews schließen den Kreis, dokumentieren Entscheidungen und stärken die Nachvollziehbarkeit.
Kontinuierliche Verbesserung und Reifegradaufbau
Dauerhafte Stabilität entsteht aus kontinuierlicher Verbesserung statt seltener Großprojekte. Etablieren Sie einen monatlichen Service-Review mit Blick auf Metriken, Incidents und Wirksamkeit von Runbooks. Reduzieren Sie Alarmrauschen systematisch und messen Sie die Zeit vom Eingang bis zur qualifizierten Analyse. Jede Änderung an Prozessen oder Technik wird mit verstärktem Monitoring begleitet und im nächsten Review ausgewertet. So wächst ein belastbarer Erfahrungsschatz.
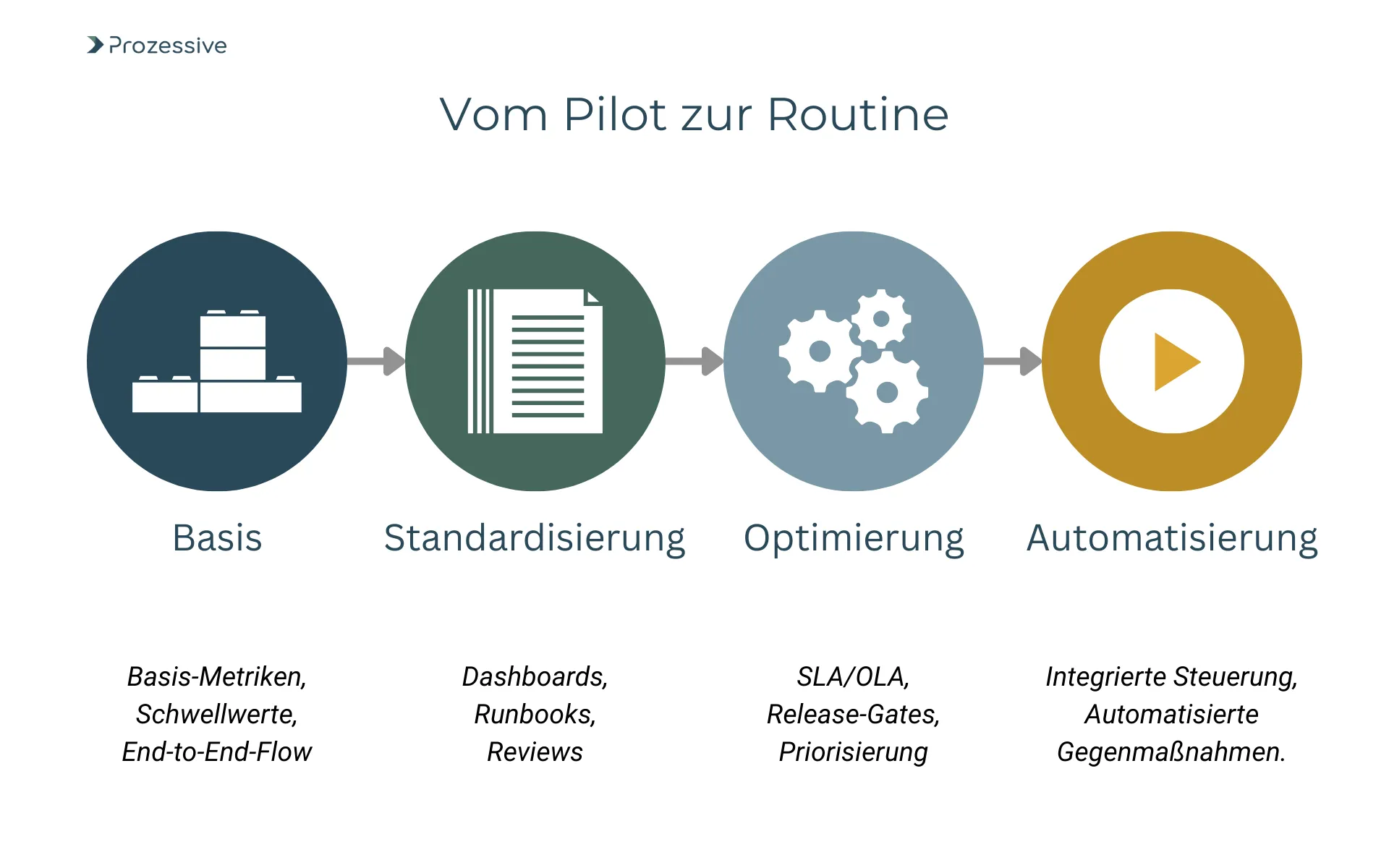
Ein praxistaugliches Reifegradbild könnte so aussehen: Phase 1 - Basis-Metriken, Schwellwerte, Alarme, ein End-to-End-Flow stabil. Phase 2 - standardisierte Felder, Dashboards, Runbooks, regelmäßige Reviews. Phase 3 - SLAs/OLAs, Release-Gates, KPI-basierte Priorisierung. Phase 4 - integrierte Risiko- und Kapazitätssteuerung, KI-spezifische Kontrollen, automatisierte Gegenmaßnahmen.
Viele KMUs erreichen Phase 2 binnen drei bis sechs Monaten, wenn Fokus und Verantwortungsübernahme klar sind.
Fazit
Monitoring macht Prozessautomatisierung belastbar, ohne Komplexität zu erzeugen. Mit wenigen, gut gewählten Kennzahlen, pragmatischen Schwellwerten und klaren Runbooks erkennen Sie Störungen früh und beheben sie zielgerichtet. Datenschutz und Governance geben den Rahmen, Reviews und ein kontinuierlicher Verbesserungsprozess sorgen für stetige Weiterentwicklung.
Starten Sie mit einem kritischen End-to-End-Prozess, definieren Sie Ziele, messen Sie konsequent und richten Sie einfache Alarme ein. Prüfen Sie danach, welche Metriken verlässlich sind, welche Lücken es gibt und welche Routinen für Ihr Unternehmen funktionieren.
So wird Digitalisierung konkret und Automatisierung bleibt verlässlich.



